publications
2024
- LLM Evaluation
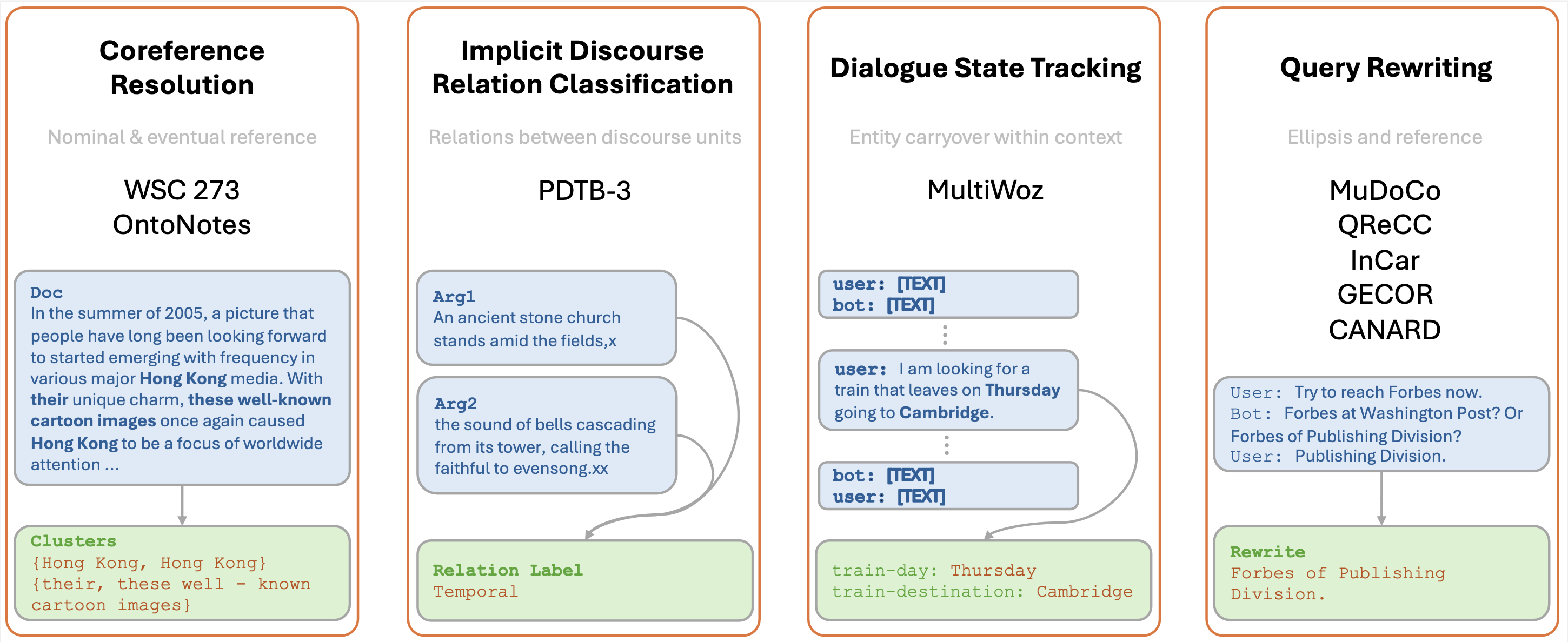 Can Large Language Models Understand Context?Yilun Zhu, Joel Moniz, Shruti Bhargava, Jiarui Lu, and 5 more authorsIn Findings of EACL 2024 , Mar 2024
Can Large Language Models Understand Context?Yilun Zhu, Joel Moniz, Shruti Bhargava, Jiarui Lu, and 5 more authorsIn Findings of EACL 2024 , Mar 2024Understanding context is key to understanding human language, an ability which Large Language Models (LLMs) have been increasingly seen to demonstrate to an impressive extent. However, though the evaluation of LLMs encompasses various domains within the realm of Natural Language Processing, limited attention has been paid to probing their linguistic capability of understanding contextual features. This paper introduces a context understanding benchmark by adapting existing datasets to suit the evaluation of generative models. This benchmark comprises of four distinct tasks and nine datasets, all featuring prompts designed to assess the models’ ability to understand context. First, we evaluate the performance of LLMs under the in-context learning pretraining scenario. Experimental results indicate that pre-trained dense models struggle with understanding more nuanced contextual features when compared to state-of-the-art fine-tuned models. Second, as LLM compression holds growing significance in both research and real-world applications, we assess the context understanding of quantized models under in-context-learning settings. We find that 3-bit post-training quantization leads to varying degrees of performance reduction on our benchmark. We conduct an extensive analysis of these scenarios to substantiate our experimental results.
@inproceedings{zhu-etal-2024-large, title = {Can Large Language Models Understand Context?}, author = {Zhu, Yilun and Moniz, Joel and Bhargava, Shruti and Lu, Jiarui and Piraviperumal, Dhivya and Li, Site and Zhang, Yuan and Yu, Hong and Tseng, Bo-Hsiang}, editor = {Graham, Yvette and Purver, Matthew}, booktitle = {Findings of EACL 2024}, month = mar, year = {2024}, address = {St. Julian{'}s, Malta}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-eacl.135}, pages = {2004--2018}, bibtex_show = true, slides = contextllm_eacl2024.pdf, poster = contextllm_poster_eacl2024.pdf, preview = contextllm.png, } - Coreference
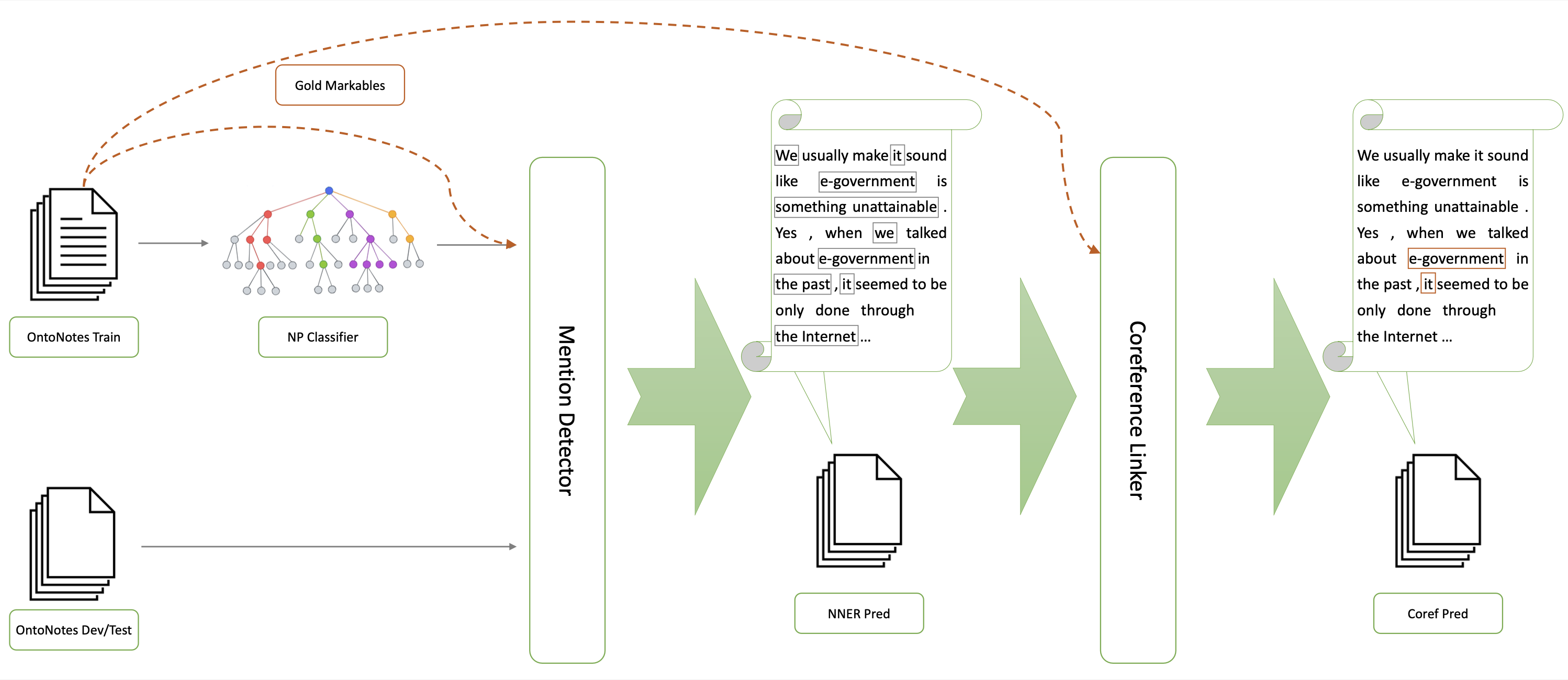 SPLICE: A Singleton-Enhanced PipeLIne for Coreference REsolutionYilun Zhu, Siyao Peng, Sameer Pradhan, and Amir ZeldesIn LREC-COLING 2024 , May 2024
SPLICE: A Singleton-Enhanced PipeLIne for Coreference REsolutionYilun Zhu, Siyao Peng, Sameer Pradhan, and Amir ZeldesIn LREC-COLING 2024 , May 2024Singleton mentions, i.e. entities mentioned only once in a text, are important to how humans understand discourse from a theoretical perspective. However previous attempts to incorporate their detection in end-to-end neural coreference resolution for English have been hampered by the lack of singleton mention spans in the OntoNotes benchmark. This paper addresses this limitation by combining predicted mentions from existing nested NER systems and features derived from OntoNotes syntax trees. With this approach, we create a near approximation of the OntoNotes dataset with all singleton mentions, achieving ~94% recall on a sample of gold singletons. We then propose a two-step neural mention and coreference resolution system, named SPLICE, and compare its performance to the end-to-end approach in two scenarios: the OntoNotes test set and the out-of-domain (OOD) OntoGUM corpus. Results indicate that reconstructed singleton training yields results comparable to end-to-end systems for OntoNotes, while improving OOD stability (+1.1 avg. F1). We conduct error analysis for mention detection and delve into its impact on coreference clustering, revealing that precision improvements deliver more substantial benefits than increases in recall for resolving coreference chains.
@inproceedings{zhu-etal-2024-splice-singleton, title = {{SPLICE}: A Singleton-Enhanced {P}ipe{LI}ne for Coreference {RE}solution}, author = {Zhu, Yilun and Peng, Siyao and Pradhan, Sameer and Zeldes, Amir}, editor = {Calzolari, Nicoletta and Kan, Min-Yen and Hoste, Veronique and Lenci, Alessandro and Sakti, Sakriani and Xue, Nianwen}, booktitle = {LREC-COLING 2024}, month = may, year = {2024}, address = {Torino, Italia}, publisher = {ELRA and ICCL}, url = {https://aclanthology.org/2024.lrec-main.1321}, pages = {15191--15201}, bibtex_show = true, slides = splice_lrec-coling2024.pdf, preview = splice.png, } - Discourse
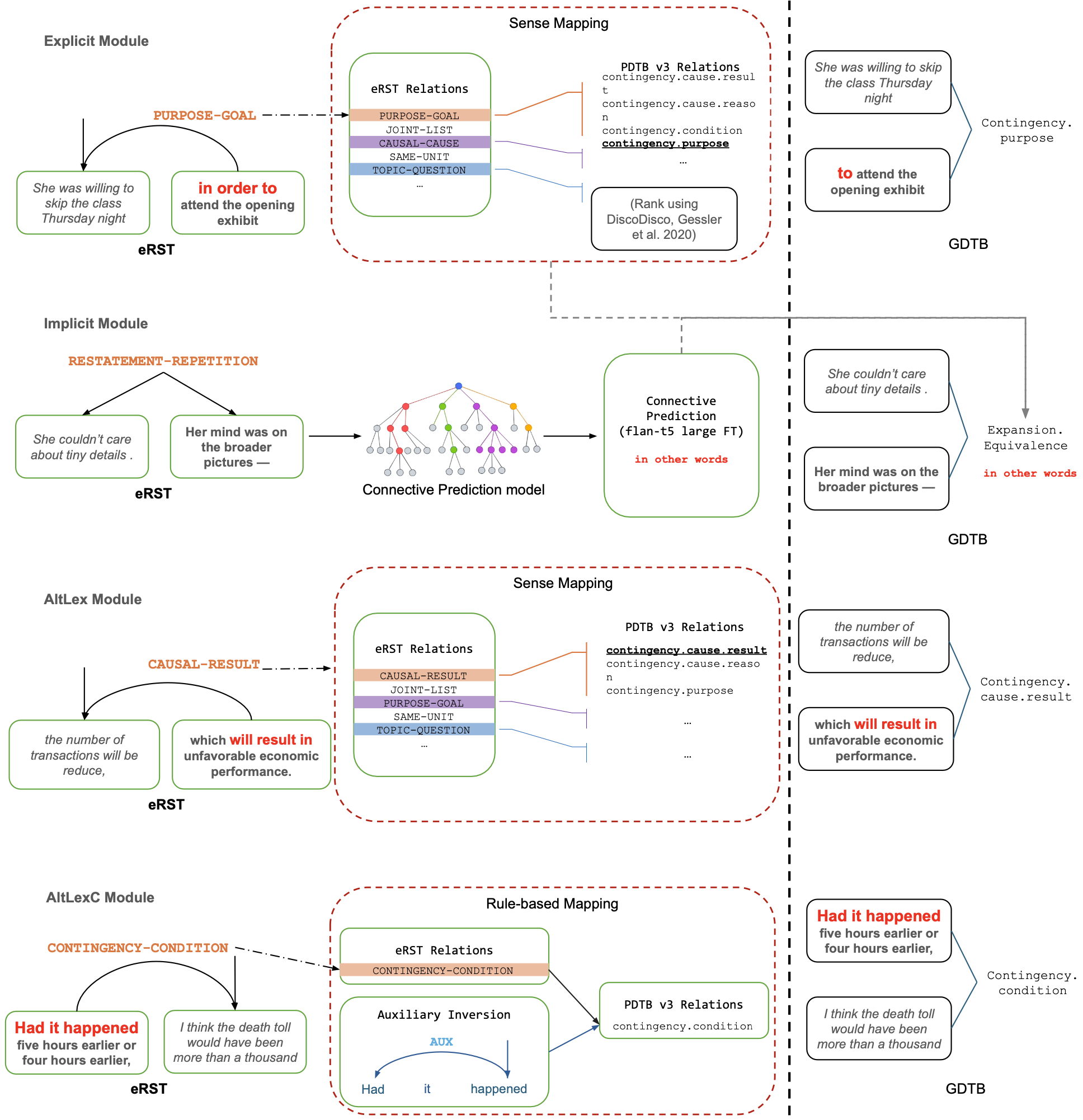 GDTB: Genre Diverse Data for English Shallow Discourse Parsing across Modalities, Text Types, and DomainsYang Janet Liu*, Tatsuya Aoyama*, Wesley Scivetti*, Yilun Zhu*, and 5 more authorsIn EMNLP 2024 , Nov 2024
GDTB: Genre Diverse Data for English Shallow Discourse Parsing across Modalities, Text Types, and DomainsYang Janet Liu*, Tatsuya Aoyama*, Wesley Scivetti*, Yilun Zhu*, and 5 more authorsIn EMNLP 2024 , Nov 2024Work on shallow discourse parsing in English has focused on the Wall Street Journal corpus, the only large-scale dataset for the language in the PDTB framework. However, the data is not openly available, is restricted to the news domain, and is by now 35 years old. In this paper, we present and evaluate a new open-access, multi-genre benchmark for PDTB-style shallow discourse parsing, based on the existing UD English GUM corpus, for which discourse relation annotations in other frameworks already exist. In a series of experiments on cross-domain relation classification, we show that while our dataset is compatible with PDTB, substantial out-of-domain degradation is observed, which can be alleviated by joint training on both datasets.
@inproceedings{liu-etal-2024-gdtb, title = {{GDTB}: Genre Diverse Data for {E}nglish Shallow Discourse Parsing across Modalities, Text Types, and Domains}, author = {Liu*, Yang Janet and Aoyama*, Tatsuya and Scivetti*, Wesley and Zhu*, Yilun and Behzad, Shabnam and Levine, Lauren Elizabeth and Lin, Jessica and Tiwari, Devika and Zeldes, Amir}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {EMNLP 2024}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.emnlp-main.684}, pages = {12287--12303}, bibtex_show = true, preview = gdtb.png, poster = gdtb_poster_emnlp2024.pdf }



2023
- Corpus
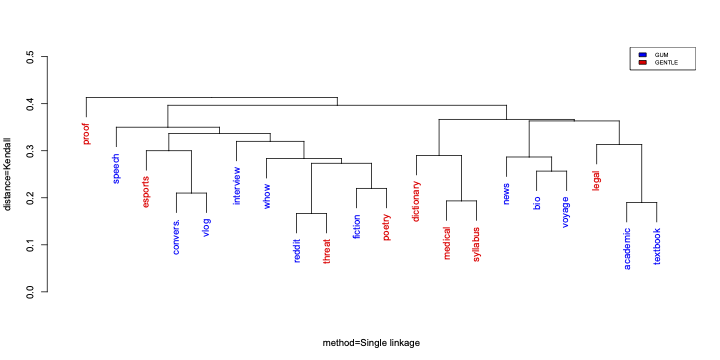 GENTLE: A Genre-Diverse Multilayer Challenge Set for English NLP and Linguistic EvaluationTatsuya Aoyama, Shabnam Behzad, Luke Gessler, Lauren Levine, and 5 more authorsIn LAW-XVII workshop @ ACL 2023 , Jul 2023
GENTLE: A Genre-Diverse Multilayer Challenge Set for English NLP and Linguistic EvaluationTatsuya Aoyama, Shabnam Behzad, Luke Gessler, Lauren Levine, and 5 more authorsIn LAW-XVII workshop @ ACL 2023 , Jul 2023We present GENTLE, a new mixed-genre English challenge corpus totaling 17K tokens and consisting of 8 unusual text types for out-of-domain evaluation: dictionary entries, esports commentaries, legal documents, medical notes, poetry, mathematical proofs, syllabuses, and threat letters. GENTLE is manually annotated for a variety of popular NLP tasks, including syntactic dependency parsing, entity recognition, coreference resolution, and discourse parsing. We evaluate state-of-the-art NLP systems on GENTLE and find severe degradation for at least some genres in their performance on all tasks, which indicates GENTLE’s utility as an evaluation dataset for NLP systems.
@inproceedings{aoyama-etal-2023-gentle, title = {{GENTLE}: A Genre-Diverse Multilayer Challenge Set for {E}nglish {NLP} and Linguistic Evaluation}, author = {Aoyama, Tatsuya and Behzad, Shabnam and Gessler, Luke and Levine, Lauren and Lin, Jessica and Liu, Yang Janet and Peng, Siyao and Zhu, Yilun and Zeldes, Amir}, editor = {Prange, Jakob and Friedrich, Annemarie}, booktitle = {LAW-XVII workshop @ ACL 2023}, month = jul, year = {2023}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.law-1.17}, doi = {10.18653/v1/2023.law-1.17}, pages = {166--178}, bibtex_show = true, preview = law2023clustering.png, } - Coreference
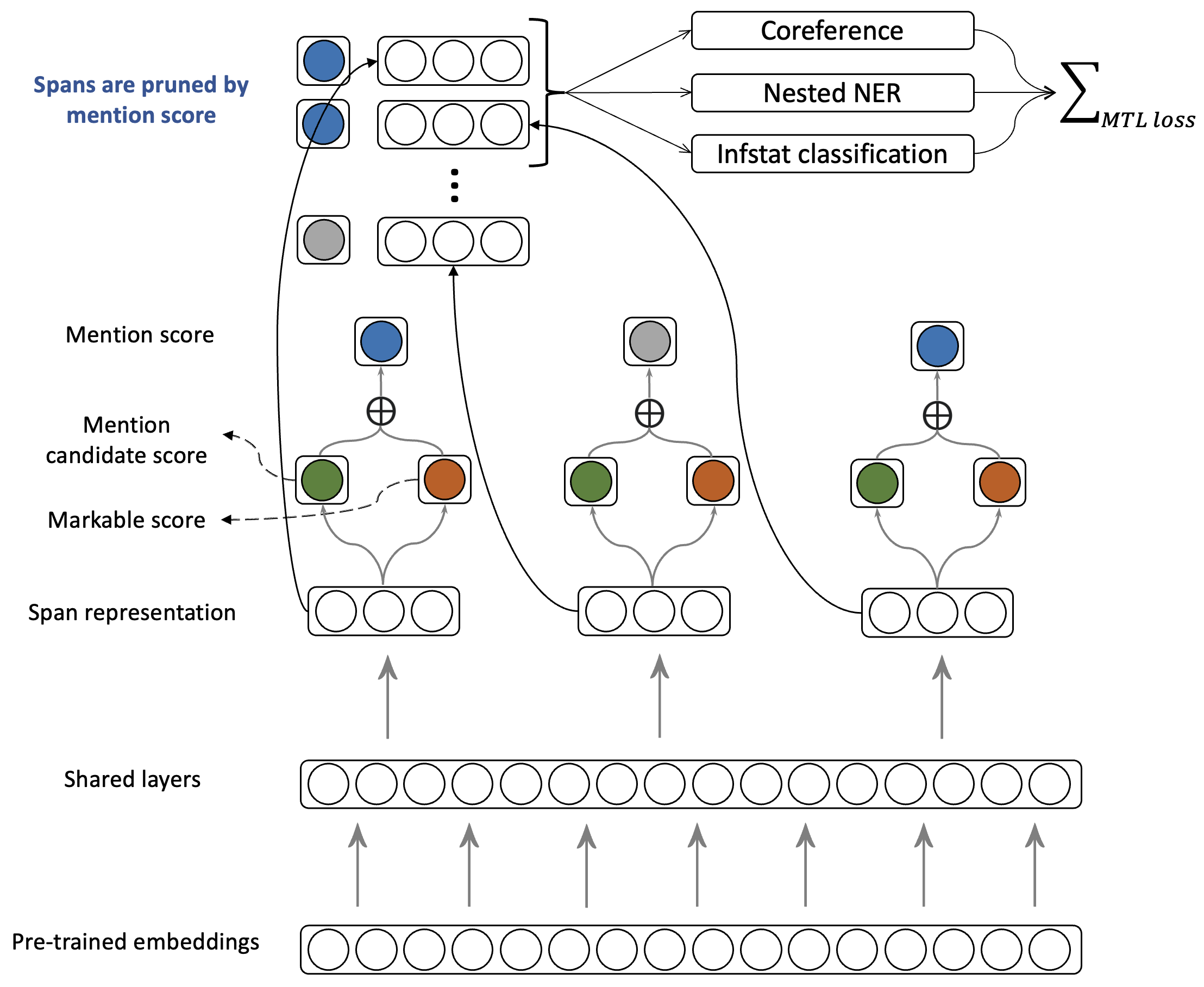 Incorporating Singletons and Mention-based Features in Coreference Resolution via Multi-task Learning for Better GeneralizationYilun Zhu, Siyao Peng, Sameer Pradhan, and Amir ZeldesIn IJCNLP-AACL 2023 , Nov 2023
Incorporating Singletons and Mention-based Features in Coreference Resolution via Multi-task Learning for Better GeneralizationYilun Zhu, Siyao Peng, Sameer Pradhan, and Amir ZeldesIn IJCNLP-AACL 2023 , Nov 2023Previous attempts to incorporate a mention detection step into end-to-end neural coreference resolution for English have been hampered by the lack of singleton mention span data as well as other entity information. This paper presents a coreference model that learns singletons as well as features such as entity type and information status via a multi-task learning-based approach. This approach achieves new stateof-the-art scores on the OntoGUM benchmark (+2.7 points) and increases robustness on multiple out-of-domain datasets (+2.3 points on average), likely due to greater generalizability for mention detection and utilization of more data from singletons when compared to only coreferent mention pair matching.
@inproceedings{zhu-etal-2023-incorporating, title = {Incorporating Singletons and Mention-based Features in Coreference Resolution via Multi-task Learning for Better Generalization}, author = {Zhu, Yilun and Peng, Siyao and Pradhan, Sameer and Zeldes, Amir}, editor = {Park, Jong C. and Arase, Yuki and Hu, Baotian and Lu, Wei and Wijaya, Derry and Purwarianti, Ayu and Krisnadhi, Adila Alfa}, booktitle = {IJCNLP-AACL 2023}, month = nov, year = {2023}, address = {Nusa Dua, Bali}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.ijcnlp-short.14}, doi = {10.18653/v1/2023.ijcnlp-short.14}, pages = {121--130}, bibtex_show = true, slides = coref_mtl_aacl2023.pdf, preview = coref_mtl.png, }


2022
- Coreference
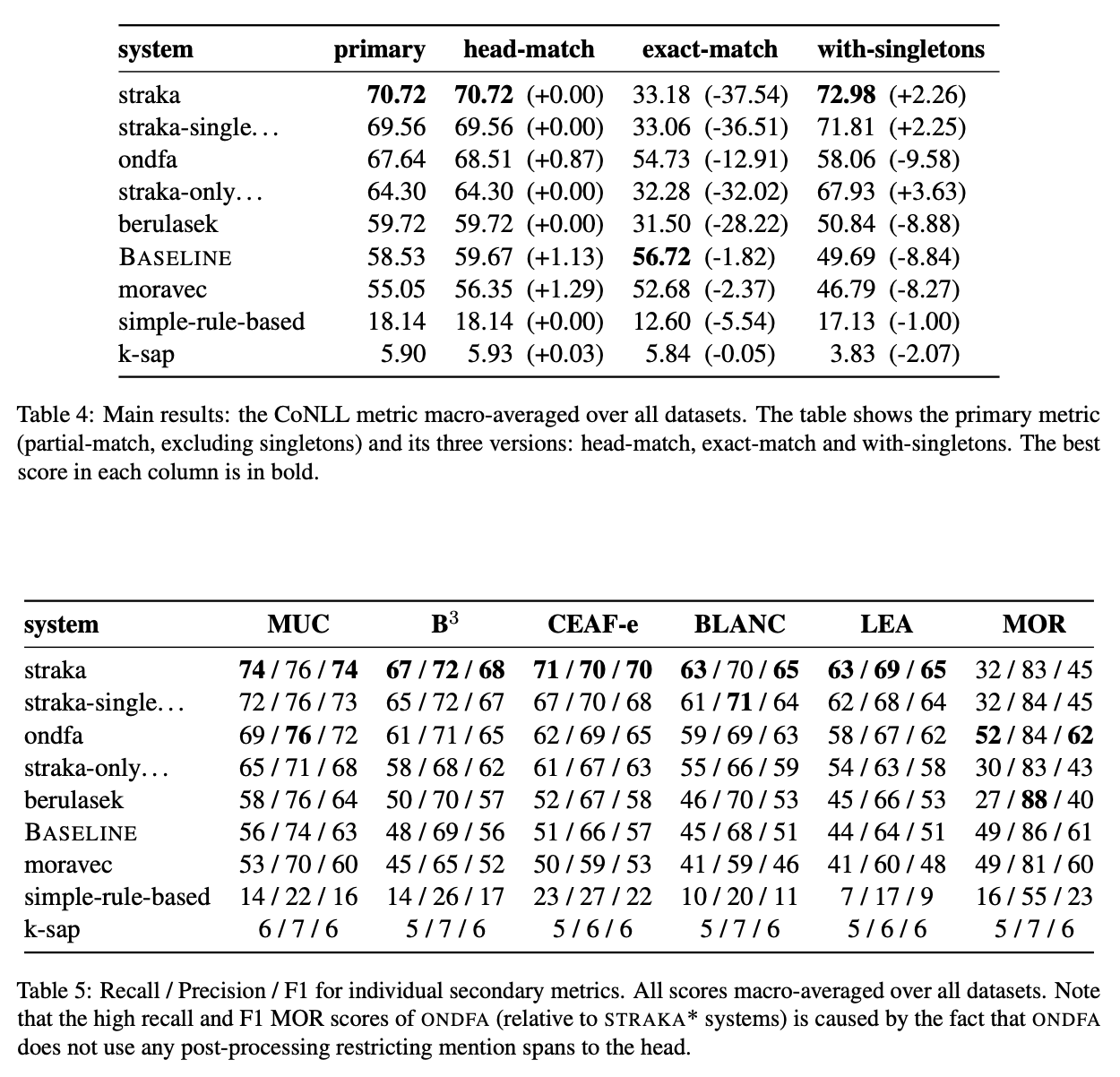
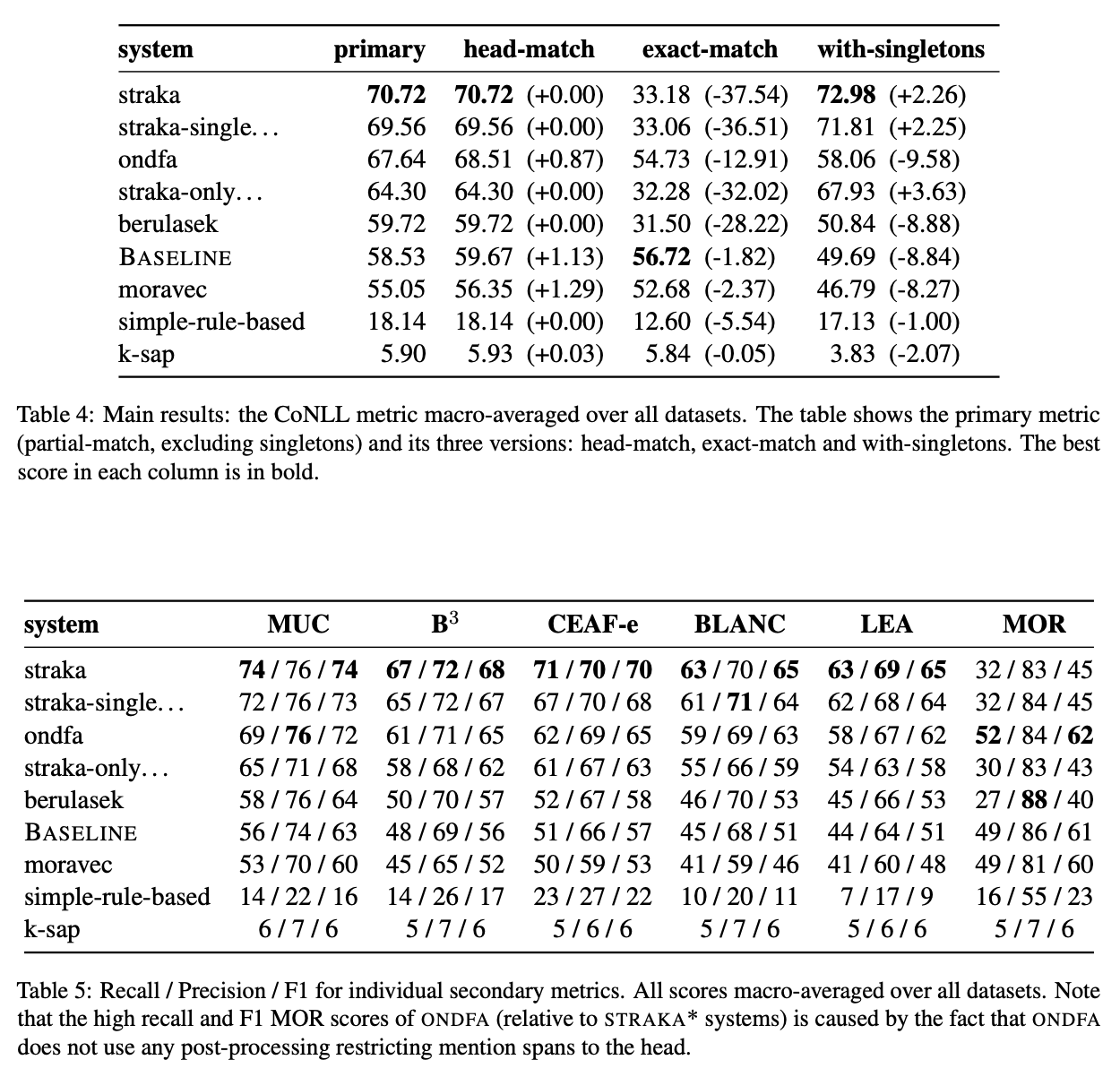 Findings of the Shared Task on Multilingual Coreference ResolutionZdeněk Žabokrtský, Miloslav Konopı́k, Anna Nedoluzhko, Michal Novák, and 6 more authorsIn CRAC workshop @ COLING 2022 , Oct 2022
Findings of the Shared Task on Multilingual Coreference ResolutionZdeněk Žabokrtský, Miloslav Konopı́k, Anna Nedoluzhko, Michal Novák, and 6 more authorsIn CRAC workshop @ COLING 2022 , Oct 2022This paper presents an overview of the shared task on multilingual coreference resolution associated with the CRAC 2022 workshop. Shared task participants were supposed to develop trainable systems capable of identifying mentions and clustering them according to identity coreference. The public edition of CorefUD 1.0, which contains 13 datasets for 10 languages, was used as the source of training and evaluation data. The CoNLL score used in previous coreference-oriented shared tasks was used as the main evaluation metric. There were 8 coreference prediction systems submitted by 5 participating teams; in addition, there was a competitive Transformer-based baseline system provided by the organizers at the beginning of the shared task. The winner system outperformed the baseline by 12 percentage points (in terms of the CoNLL scores averaged across all datasets for individual languages).
@inproceedings{zabokrtsky-etal-2022-findings, title = {Findings of the Shared Task on Multilingual Coreference Resolution}, author = {{\v{Z}}abokrtsk{\'y}, Zden{\v{e}}k and Konop{\'\i}k, Miloslav and Nedoluzhko, Anna and Nov{\'a}k, Michal and Ogrodniczuk, Maciej and Popel, Martin and Pra{\v{z}}{\'a}k, Ond{\v{r}}ej and Sido, Jakub and Zeman, Daniel and Zhu, Yilun}, editor = {{\v{Z}}abokrtsk{\'y}, Zden{\v{e}}k and Ogrodniczuk, Maciej}, booktitle = {CRAC workshop @ COLING 2022}, month = oct, year = {2022}, address = {Gyeongju, Republic of Korea}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.crac-mcr.1}, pages = {1--17}, bibtex_show = true, preview = mcr.png, }

2021
- Corpus
 Overview of AMALGUM – Large Silver Quality Annotations across English GenresLuke Gessler, Siyao Peng, Yang Liu, Yilun Zhu, and 2 more authorsIn SCiL 2021 , Feb 2021
Overview of AMALGUM – Large Silver Quality Annotations across English GenresLuke Gessler, Siyao Peng, Yang Liu, Yilun Zhu, and 2 more authorsIn SCiL 2021 , Feb 2021@inproceedings{gessler-etal-2021-overview, title = {Overview of {AMALGUM} {--} Large Silver Quality Annotations across {E}nglish Genres}, author = {Gessler, Luke and Peng, Siyao and Liu, Yang and Zhu, Yilun and Behzad, Shabnam and Zeldes, Amir}, editor = {Ettinger, Allyson and Pavlick, Ellie and Prickett, Brandon}, booktitle = {SCiL 2021}, month = feb, year = {2021}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.scil-1.52}, pages = {434--437}, bibtex_show = true, preview = update_amalgum.png, } - Coreference
 OntoGUM: Evaluating Contextualized SOTA Coreference Resolution on 12 More GenresYilun Zhu, Sameer Pradhan, and Amir ZeldesIn ACL-IJCNLP 2021 , Aug 2021
OntoGUM: Evaluating Contextualized SOTA Coreference Resolution on 12 More GenresYilun Zhu, Sameer Pradhan, and Amir ZeldesIn ACL-IJCNLP 2021 , Aug 2021SOTA coreference resolution produces increasingly impressive scores on the OntoNotes benchmark. However lack of comparable data following the same scheme for more genres makes it difficult to evaluate generalizability to open domain data. This paper provides a dataset and comprehensive evaluation showing that the latest neural LM based end-to-end systems degrade very substantially out of domain. We make an OntoNotes-like coreference dataset called OntoGUM publicly available, converted from GUM, an English corpus covering 12 genres, using deterministic rules, which we evaluate. Thanks to the rich syntactic and discourse annotations in GUM, we are able to create the largest human-annotated coreference corpus following the OntoNotes guidelines, and the first to be evaluated for consistency with the OntoNotes scheme. Out-of-domain evaluation across 12 genres shows nearly 15-20% degradation for both deterministic and deep learning systems, indicating a lack of generalizability or covert overfitting in existing coreference resolution models.
@inproceedings{zhu-etal-2021-ontogum, title = {{O}nto{GUM}: Evaluating Contextualized {SOTA} Coreference Resolution on 12 More Genres}, author = {Zhu, Yilun and Pradhan, Sameer and Zeldes, Amir}, editor = {Zong, Chengqing and Xia, Fei and Li, Wenjie and Navigli, Roberto}, booktitle = {ACL-IJCNLP 2021}, month = aug, year = {2021}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.acl-short.59}, doi = {10.18653/v1/2021.acl-short.59}, pages = {461--467}, bibtex_show = true, slides = ontogum_acl2021.pdf, preview = ontogum.png, } - Discourse
 DisCoDisCo at the DISRPT2021 Shared Task: A System for Discourse Segmentation, Classification, and Connective DetectionLuke Gessler, Shabnam Behzad, Yang Janet Liu, Siyao Peng, and 2 more authorsIn DISRPT workshop @ EMNLP 2021 , Nov 2021
DisCoDisCo at the DISRPT2021 Shared Task: A System for Discourse Segmentation, Classification, and Connective DetectionLuke Gessler, Shabnam Behzad, Yang Janet Liu, Siyao Peng, and 2 more authorsIn DISRPT workshop @ EMNLP 2021 , Nov 2021This paper describes our submission to the DISRPT2021 Shared Task on Discourse Unit Segmentation, Connective Detection, and Relation Classification. Our system, called DisCoDisCo, is a Transformer-based neural classifier which enhances contextualized word embeddings (CWEs) with hand-crafted features, relying on tokenwise sequence tagging for discourse segmentation and connective detection, and a feature-rich, encoder-less sentence pair classifier for relation classification. Our results for the first two tasks outperform SOTA scores from the previous 2019 shared task, and results on relation classification suggest strong performance on the new 2021 benchmark. Ablation tests show that including features beyond CWEs are helpful for both tasks, and a partial evaluation of multiple pretrained Transformer-based language models indicates that models pre-trained on the Next Sentence Prediction (NSP) task are optimal for relation classification.
@inproceedings{gessler-etal-2021-discodisco, title = {{D}is{C}o{D}is{C}o at the {DISRPT}2021 Shared Task: A System for Discourse Segmentation, Classification, and Connective Detection}, author = {Gessler, Luke and Behzad, Shabnam and Liu, Yang Janet and Peng, Siyao and Zhu, Yilun and Zeldes, Amir}, editor = {Zeldes, Amir and Liu, Yang Janet and Iruskieta, Mikel and Muller, Philippe and Braud, Chlo{\'e} and Badene, Sonia}, booktitle = {DISRPT workshop @ EMNLP 2021}, month = nov, year = {2021}, address = {Punta Cana, Dominican Republic}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.disrpt-1.6}, doi = {10.18653/v1/2021.disrpt-1.6}, pages = {51--62}, bibtex_show = true, preview = disrpt2021.png, } - Coreference Anatomy of OntoGUM—Adapting GUM to the OntoNotes Scheme to Evaluate Robustness of SOTA Coreference AlgorithmsYilun Zhu, Sameer Pradhan, and Amir ZeldesIn CRAC workshop @ EMNLP 2021 , Nov 2021
SOTA coreference resolution produces increasingly impressive scores on the OntoNotes benchmark. However lack of comparable data following the same scheme for more genres makes it difficult to evaluate generalizability to open domain data. Zhu et al. (2021) introduced the creation of the OntoGUM corpus for evaluating geralizability of the latest neural LM-based end-to-end systems. This paper covers details of the mapping process which is a set of deterministic rules applied to the rich syntactic and discourse annotations manually annotated in the GUM corpus. Out-of-domain evaluation across 12 genres shows nearly 15-20% degradation for both deterministic and deep learning systems, indicating a lack of generalizability or covert overfitting in existing coreference resolution models.
@inproceedings{zhu-etal-2021-anatomy, title = {Anatomy of {O}nto{GUM}{---}{A}dapting {GUM} to the {O}nto{N}otes Scheme to Evaluate Robustness of {SOTA} Coreference Algorithms}, author = {Zhu, Yilun and Pradhan, Sameer and Zeldes, Amir}, editor = {Ogrodniczuk, Maciej and Pradhan, Sameer and Poesio, Massimo and Grishina, Yulia and Ng, Vincent}, booktitle = {CRAC workshop @ EMNLP 2021}, month = nov, year = {2021}, address = {Punta Cana, Dominican Republic}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.crac-1.15}, doi = {10.18653/v1/2021.crac-1.15}, pages = {141--149}, bibtex_show = true, preview = ontogum.png, }



2020
- Corpus
 A Corpus of Adpositional Supersenses for Mandarin ChineseSiyao Peng, Yang Liu, Yilun Zhu, Austin Blodgett, and 2 more authorsIn LREC 2020 , May 2020
A Corpus of Adpositional Supersenses for Mandarin ChineseSiyao Peng, Yang Liu, Yilun Zhu, Austin Blodgett, and 2 more authorsIn LREC 2020 , May 2020Adpositions are frequent markers of semantic relations, but they are highly ambiguous and vary significantly from language to language. Moreover, there is a dearth of annotated corpora for investigating the cross-linguistic variation of adposition semantics, or for building multilingual disambiguation systems. This paper presents a corpus in which all adpositions have been semantically annotated in Mandarin Chinese; to the best of our knowledge, this is the first Chinese corpus to be broadly annotated with adposition semantics. Our approach adapts a framework that defined a general set of supersenses according to ostensibly language-independent semantic criteria, though its development focused primarily on English prepositions (Schneider et al., 2018). We find that the supersense categories are well-suited to Chinese adpositions despite syntactic differences from English. On a Mandarin translation of The Little Prince, we achieve high inter-annotator agreement and analyze semantic correspondences of adposition tokens in bitext.
@inproceedings{peng-etal-2020-corpus, title = {A Corpus of Adpositional Supersenses for {M}andarin {C}hinese}, author = {Peng, Siyao and Liu, Yang and Zhu, Yilun and Blodgett, Austin and Zhao, Yushi and Schneider, Nathan}, booktitle = {LREC 2020}, month = may, year = {2020}, address = {Marseille, France}, publisher = {European Language Resources Association}, url = {https://aclanthology.org/2020.lrec-1.733}, pages = {5986--5994}, language = {English}, isbn = {979-10-95546-34-4}, bibtex_show = true, preview = supersenses.png, } - Corpus AMALGUM – A Free, Balanced, Multilayer English Web CorpusLuke Gessler, Siyao Peng, Yang Liu, Yilun Zhu, and 2 more authorsIn LREC 2020 , May 2020
We present a freely available, genre-balanced English web corpus totaling 4M tokens and featuring a large number of high-quality automatic annotation layers, including dependency trees, non-named entity annotations, coreference resolution, and discourse trees in Rhetorical Structure Theory. By tapping open online data sources the corpus is meant to offer a more sizable alternative to smaller manually created annotated data sets, while avoiding pitfalls such as imbalanced or unknown composition, licensing problems, and low-quality natural language processing. We harness knowledge from multiple annotation layers in order to achieve a “better than NLP” benchmark and evaluate the accuracy of the resulting resource.
@inproceedings{gessler-etal-2020-amalgum, title = {{AMALGUM} {--} A Free, Balanced, Multilayer {E}nglish Web Corpus}, author = {Gessler, Luke and Peng, Siyao and Liu, Yang and Zhu, Yilun and Behzad, Shabnam and Zeldes, Amir}, editor = {Calzolari, Nicoletta and B{\'e}chet, Fr{\'e}d{\'e}ric and Blache, Philippe and Choukri, Khalid and Cieri, Christopher and Declerck, Thierry and Goggi, Sara and Isahara, Hitoshi and Maegaard, Bente and Mariani, Joseph and Mazo, H{\'e}l{\`e}ne and Moreno, Asuncion and Odijk, Jan and Piperidis, Stelios}, booktitle = {LREC 2020}, month = may, year = {2020}, address = {Marseille, France}, publisher = {European Language Resources Association}, url = {https://aclanthology.org/2020.lrec-1.648}, pages = {5267--5275}, language = {English}, isbn = {979-10-95546-34-4}, bibtex_show = true, preview = update_amalgum.png, }

2019
- Corpus Adpositional Supersenses for Mandarin ChineseYilun Zhu, Yang Janet Liu, Siyao Peng, Austin Blodgett, and 2 more authorsIn SCiL 2019 , Jan 2019
This study adapts Semantic Network of Adposition and Case Supersenses (SNACS) annotation to Mandarin Chinese and demonstrates that the same supersense categories are appropriate for Chinese adposition semantics. We annotated 15 chapters of The Little Prince, with high interannotator agreement. The parallel corpus gives insight into differences in construal between the two languages’ adpositions, namely a number of construals that are frequent in Chinese but rare or unattested in the English corpus. The annotated corpus can further support automatic disambiguation of adpositions in Chinese, and the common inventory of supersenses between the two languages can potentially serve cross-linguistic tasks such as machine translation.
@inproceedings{Zhu2019AdpositionalSF, title = {Adpositional Supersenses for Mandarin Chinese}, author = {Zhu, Yilun and Liu, Yang Janet and Peng, Siyao and Blodgett, Austin and Zhao, Yushi and Schneider, Nathan}, booktitle = {SCiL 2019}, month = jan, year = {2019}, address = {}, publisher = {The Society for Computation in Linguistics}, volume = {2, article 40}, url = {https://scholarworks.umass.edu/cgi/viewcontent.cgi?article=1090&context=scil}, doi = {https://doi.org/10.7275/ne25-d350}, bibtex_show = true, preview = supersenses.png, } - Discourse
 GumDrop at the DISRPT2019 Shared Task: A Model Stacking Approach to Discourse Unit Segmentation and Connective DetectionYue Yu, Yilun Zhu, Yang Liu, Yan Liu, and 3 more authorsIn DISRPT workshop @ NAACL 2019 , Jun 2019
GumDrop at the DISRPT2019 Shared Task: A Model Stacking Approach to Discourse Unit Segmentation and Connective DetectionYue Yu, Yilun Zhu, Yang Liu, Yan Liu, and 3 more authorsIn DISRPT workshop @ NAACL 2019 , Jun 2019In this paper we present GumDrop, Georgetown University’s entry at the DISRPT 2019 Shared Task on automatic discourse unit segmentation and connective detection. Our approach relies on model stacking, creating a heterogeneous ensemble of classifiers, which feed into a metalearner for each final task. The system encompasses three trainable component stacks: one for sentence splitting, one for discourse unit segmentation and one for connective detection. The flexibility of each ensemble allows the system to generalize well to datasets of different sizes and with varying levels of homogeneity.
@inproceedings{yu-etal-2019-gumdrop, title = {{G}um{D}rop at the {DISRPT}2019 Shared Task: A Model Stacking Approach to Discourse Unit Segmentation and Connective Detection}, author = {Yu, Yue and Zhu, Yilun and Liu, Yang and Liu, Yan and Peng, Siyao and Gong, Mackenzie and Zeldes, Amir}, editor = {Zeldes, Amir and Das, Debopam and Galani, Erick Maziero and Antonio, Juliano Desiderato and Iruskieta, Mikel}, booktitle = {DISRPT workshop @ NAACL 2019}, month = jun, year = {2019}, address = {Minneapolis, MN}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/W19-2717}, doi = {10.18653/v1/W19-2717}, pages = {133--143}, bibtex_show = true, preview = rstweb3_signals.png, }
